
The value of evidence rubrics
First posted on Khulisa Management Services
Last year I wrote a blog on the growing popularity of rubrics at evaluation conferences and their increasing application in real world monitoring and evaluation. Rubrics can be used in lots of different ways, and in this blog, I’ll explain why I’ve found them useful to assess the quality of evidence.
What are rubrics?
For those of you that are new to the term, rubrics are essentially a form of qualitative scale that includes:
(i) performance criteria;
(ii) standards (i.e., levels of performance), and;
(iii) descriptors (explanation of what the level looks like).
Even if we haven’t all used rubrics, we’ve all been assessed by them. The grades you get for writing essays in school or university were likely to be determined, in part, using rubrics (see here for an explanation from the University of Edinburgh on why rubrics allow for quicker and more consistent marking).
All rubrics have some form of scale that denotes levels of performance. Like any scale, rubrics illustrate what the difference between good and bad is. They help to determine what’s in and what’s out, and what meets the grade and what doesn’t. But they do more than simply assign a number (1, 2, 3), letter (A, B, C) or word (good/bad) to a performance metric. Rubrics explain what the standard means, and they make clear the reasoning behind an assessment. This makes them particularly helpful for making transparent evaluative judgements about performance or expressing levels of confidence in contribution towards a particular outcome, especially for complex change processes where several actors might make important contributions to that outcome.
Contribution rubrics
A few years ago, I developed a method called “Contribution Rubrics” which I also shared at the European Evaluation Conference (EES) a few weeks ago. Contribution Rubrics is essentially a combination of Outcome Harvesting and Process Tracing I developed during an evaluation in Côte d’Ivoire for CARE International. At around about the same time, I developed some evidence criteria and standards which sat behind a Qualitative Comparative Analysis (QCA) of CARE’s advocacy outcomes over the last decade. One key aspect of Contribution Rubrics is that we should not only want to appraise the significance of an outcome and the level of contribution towards that outcome, but also how good our evidence is underpinning a judgement about contribution to that outcome.
Over the last few years, Contribution Rubrics has been used in several evaluations across various organisations. Despite this, I knew that many programme staff and evaluators wouldn’t have the time to carry out the method in full. So, I considered how some of the elements of Contribution Rubrics might be applied by those who didn't have the time to carry out the method in full, but still might want to come to a better-informed judgement about how credible a case study or Outcome Harvesting outcome statement was, for example.
Evidence rubrics
What came out of that was what a set of rubrics that could be applied to case-based or qualitative approaches to evaluation more broadly.
It’s always best to stand on the shoulder of others. So, in order to define the rubrics I build off the UK Department for International Development’s (DFID) Strength of Evidence Guidance, Bond’s Principles and Checklist for Assessing the Quality of Evidence, Nesta’s Standards of Evidence, among others. The 5 criteria I chose for assessing standards of case-based evidence were: (1) plausibility; (2) uniqueness;(3) triangulation; (4) transparency, and; (5) independence, as you can see illustrated below:

For each criterion I created a five-point scale such as the one below for triangulation:
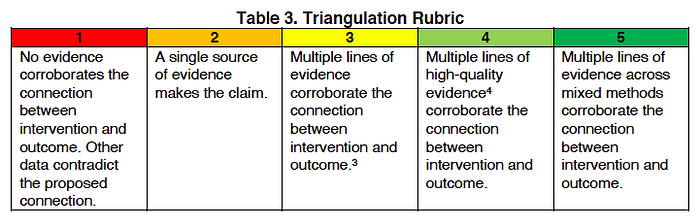
Since developing the rubrics I’ve mostly used them to help monitoring and evaluation teams carrying out adaptations of Outcome Harvesting. This was timely, as the Dutch Policy and Operations Evaluation Department (IOB) recently gave an excoriating criticism of the method for apparent weaknesses in terms of independence, triangulation, and bias. These rubrics can help with all three.
Rubrics are intended to be versatile. You can choose different weights for the relative importance of the five criteria I selected, you can adapt the descriptors in the boxes, you can choose fewer or more levels in a scale. You can even choose different criteria entirely. Whichever way you might want to play around with the specifics, rubrics like these should help you to make your evaluative judgements more structured, transparent, and credible. Using these rubrics can also help you make better choices before you even collect data because they will help you define (and potentially raise) standards beforehand.
Perhaps more important than the specific criteria, standards, and descriptors I chose though, is the message that various evaluators are doing similar things to structure their findings and judgements for more qualitative and case-based methods. Various reputable evaluation outfits have told me so (see here for an example from The TAP Room Consultants on how to structure evaluative judgements, and also here from the Laudes Foundation on rubrics for understanding contribution to systems change).
We should also take note that other sectors such as the legal profession have been using different standards of proof for different judgements for decades. So, this approach isn’t that controversial. Consider the difference between the “balance of probabilities” and “beyond reasonable doubt.” Clearly, the latter would require a higher standard of evidence.
In my view, evidence rubrics can even be applied more broadly. If you’re a programme or portfolio manager, you might want to consider how you would make use of the scores for decision-making. For example, in one instance, I used the rubrics to determine which case studies were good enough to be included in an annual report. In another few instances, like The TAP Room example, I used the rubrics to help organise summary judgements. If a manager wants to take more evidence-based decisions, they could use a form of rubrics like these evidence rubrics to determine what programming decisions to take. They might consider what would be the appropriate level (or score) required to adapt parts of a project or programme, scale up certain parts of the projects if there is credible evidence of achievement, scale down other parts if there isn’t, or even close down whole projects if they don’t meet the passing grade. If we’re really committed to evidence-based policy beyond the fetish of Randomised Control Trials (RCTs), then evidence rubrics are a good place to start.









![[Frame for Work] The Landscape of Knowledge Engagement (KE, v4)](https://miro.medium.com/v2/resize:fit:679/1*bP9HYiOTcPnbO0E-Gu4fIg.jpeg)